Performance
This page is about advanced topics. Please skip it if you are a beginner.
This page explains typical MPS memory consumption and performance bottlenecks and how to solve those problems. If you want to know about slow software in general (e.g., hardware-related slowness), read Slow Software | Ink & Switch ⧉.
How are expensive model traversals handled in MPS?
There is no API for indexing model traversal results (e.g., getParent(), getAncestors()) the way frameworks like Xtext implement it.
The implementation of Find usages of concepts is efficient, though. The internal class FastNodeFinderManager can efficiently return the list of instances of a concept for a model. ConceptDescendantsCache ⧉ also caches the descendants of a concept.
The startup indexing collects information about MPS models, such as instances of concepts, imports, and property values (used for the Find Text in Node Properties action). The virtual files ⧉ representing root nodes in the filesystem are probably also indexed.
The initial indexing also integrates Base Language into the IntelliJ search functionality (implementation in MPS). As an IntelliJ plugin, MPS should allow the standard search for usages and structural search ⧉ to work with Base Language classes and interfaces.
General¶
- Read the page Advanced Configuration ⧉ in the official documentation. You are especially interested in setting
-Xmxand-Xms. - Do not invalidate the cache when restarting the project if it isn't necessary. The reindexing can take a while for large projects.
- Speeding up model checks with Scope Cache ⧉ (< MPS 2021.2)
- Often accessed data should be cached (How to implement caching in Java ⧉)
- Don't recalculate expensive calculations but rather save the results in variables.
- Different data structures have other time and space complexities. For example, selecting a different list implementation can have significant improvements on performance (Big-O Cheat Sheet ⧉). Do not always use lists. Check if another data structure might be better suitable such as hash maps.
- The collections language has a significant overhead in comparison to plain Java. If you need better performance, use the Java
foreachstatement and notcollection.forEachand consider avoid the language in general for performance-critical code. You can improve especially list iteration that way. - Make sure to iterate nodes or editor cell trees efficiently. Narrow down the nodes that you want to iterate over, for example,
model.roots(ClassConcept)instead ofmodel.nodes(<all>).nodesIncludingImported()can also create immense scopes. The same is true for searching in the console: avoid snippets such as#nodes<scope = global>should be avoided. For deep structures,node.descendantscan also be expensive. - When using scopes, avoid using a GlobalScope ⧉. Try to also use the following snippets for filtering models that often shouldn't be searched because they are not indexed:
#modules.where({~it => it.isPackaged() })to filter out modules that are installed#models.where({~it => TemporaryModels.isTemporary(it) })to filter temporary models
- Throwing exceptions and especially fatal errors shown in the window's lower right corner is slow. Short freezes before MPS throws the errors are sometimes the result of that.
Generator¶
-
Disabling transient models through the button in the bottom right corner of the MPS frame will increase generation performance significantly, especially with the generator option Apply transformations in place.
-
TODO: Add generator performance slides from the MPS Meetup
Model Pruning¶
Often, the generator doesn't have to process all nodes. You might have different build configurations where you are interested in only a subset of nodes or don't use cross-model generation ⧉. You copy nodes from other models to the current model instead. Sometimes additional information is attached to nodes. MPS doesn't have to generate such attributes or nodes. Having too many nodes to be processed can impact memory and slow the generator.
You can achieve Model pruning using an allowlist or blocklist approach: specify which nodes should or shouldn’t be processed. Both approaches are combinable. The following simplified approach is one possible solution to achieve this:
- Collect all original root nodes:
model.roots(<all>).select({~it => genContext.get original copied input for (it); }) - Create a pruning condition that decides which nodes can be pruned and collect the other nodes (relevant nodes). Also, list pertinent root concepts the generator shouldn't prune.
- Start from a specific node, iterate through its descendants, and follow only the references allowed by the pruning condition. You should also include other nodes that the generator needs that are not reachable by reference.
- Make copies of the roots of nodes that are relevant, and the generator shouldn't prune.
- Iterate through the children of the copies. If a child is not a relevant node, detach it from its parent node.
- Clear the original content from the input model and add the relevant roots to the input model.
Editor¶
Big Roots Render Slowly¶
The initial rendering time increases with the size of the AST. MPS tries to cache parts of the editor once built, and after the initial render, it will only update the cells that require changes, but collecting the necessary dependency information to achieve this incrementality takes time. How big is too big? Thousands of descendants are going to take several seconds to render. Calling the relayout method should be invoked sparingly (manually or programmatically).
contributed by: @sergej-koscejev
Long-Running Checking Rules on Big Roots¶
When the editor displays a root node, checking rules are run in the background. The background checker can be interrupted between rules rather than during the execution of them. When checking rules are too expensive for live checking, set the flag do not apply on the fly to true. The Type system caches calculations by default, which can also impact performance when recalculated too often.
contributed by: @sergej-koscejev
MPS Extensions¶
- The diagram ⧉ language saves layout information in node attributes. That means that automatically laying out the diagram causes a lot of changes in the diff view for this root node.. An option in the editor's diagram definition can influence auto layouting.
- Tables and diagrams turn off incremental rendering. That means the editor will not be updated incrementally, causing a full update on each typed character. It might also affect the type system calculations (MPS_EXTENSIONS-579 ⧉)
- When you use horizontal or vertical lines or any styles from de.itemis.mps.editor.celllayout.styles language (such as _grow-x or _grid-layout-flatten), a top-down layout algorithm activates for the editor. This algorithm is slower than the usual MPS re-layout, slowing down the incremental editor update.
KernelF¶
- The code coverage collection ⧉ is global. That means you either
have to empty it after some time with
DefaultCoverageAnalyzer.reset()or start the interpreter without coverage. The class IETS3ExprEvalHelper ⧉ has methods for evaluating nodes with and without coverage. - The interpreter ⧉ framework can be slow when you invoke the interpreter often. There may be faster alternatives ⧉ that are currently not implemented.
Startup¶
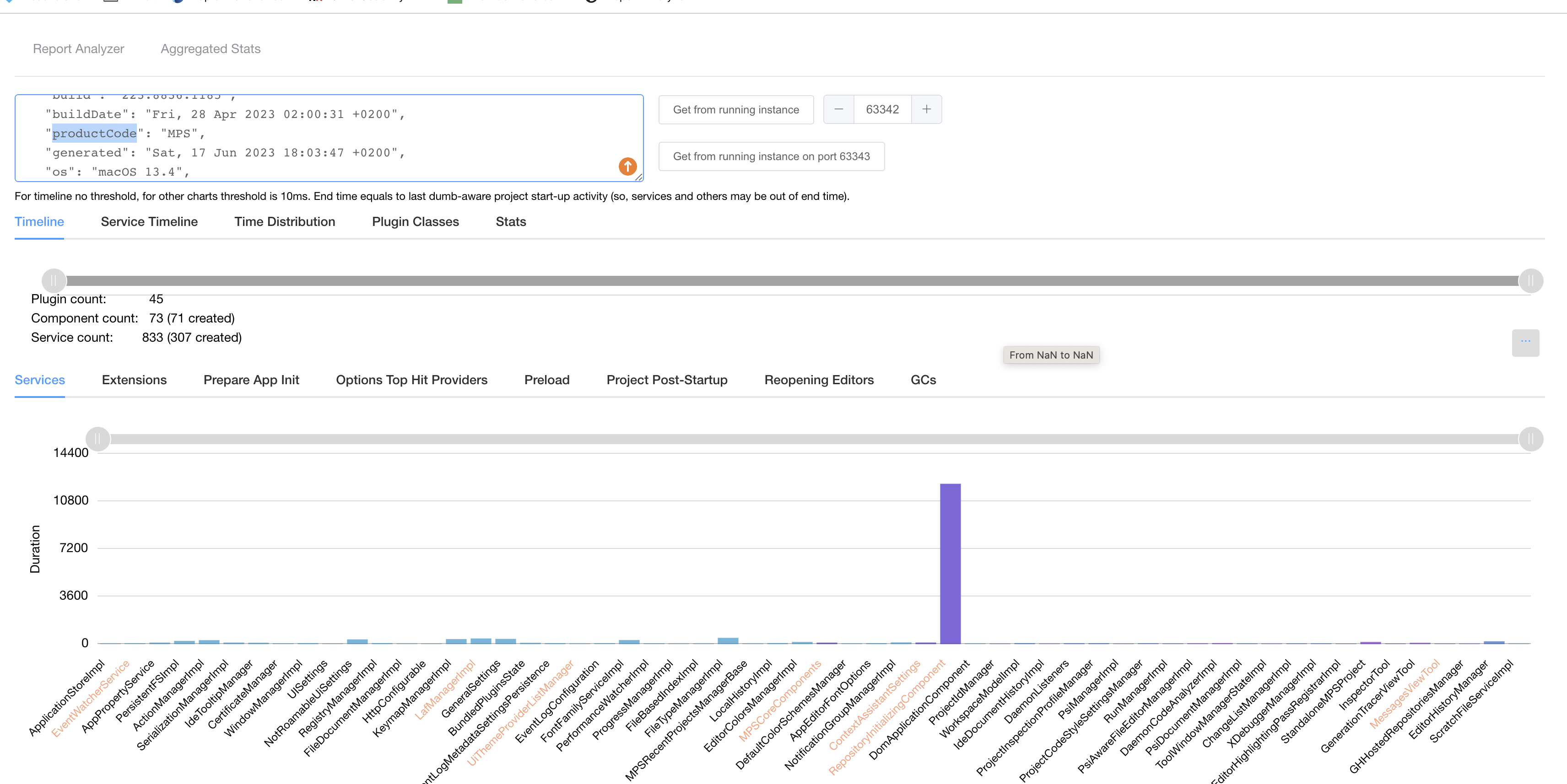
You can analyze MPS's startup with a standard Java profiler like YourKit. For IntelliJ components, services, and extensions ⧉, it is also possible to use the IntelliJ Report Analyzer ⧉. Click on the button Get from running instance to fetch the data from the opened MPS instance. Ensure that the productCode in the left text area says MPS because other IntelliJ IDEs, such as IntelliJ IDEA, use the same port.
Java¶
If you are interested in internal performance-related topics about Java and its compiler, you might find the following articles helpful:
- How the JIT compiler optimizes code | ibm.com ⧉
- The Java HotSpot Performance Engine Architecture | oracle.com ⧉
- Optimizing compiler | wikipedia.com ⧉
- How the JIT compiler boosts Java performance in OpenJDK | developers.redhat.com ⧉
- Microbenchmarking with Java | baeldung.com ⧉