New mbeddr Flyer (22 Nov 2013)
mbeddr will be featured as part of the itemis booth at the Embedded Software Engineering Kongress in December in Sindelfingen. As part of the preparation, we have created a new two-page Flyer. It provides a brief overview over mbeddr.
New mbeddr Website (04 Nov 2013)
This post is a bit funny. Because if you read it, you wouldn't have to read it, because you already know what it says. And if you don't read it, you probably should. Anyway :-)
We have new website. It is built on top of Twitter Bootstrap (like any modern website, it seems). We have actually copied the structure/code from the Xtext website (with their permission; Thanks!), so it was easy to build even though no one in the team actually knows anything about Bootstrap :-)
The only thing we haven't figured out yet is how to create an RSS feed from this News page. We'll work on that. (Anybody got an idea?) So we'll keep the blog at the wordpress site going for the time being.
Let us know what you think about the new site (design and content).
Eclipse Proposal for mbeddr available (29 Oct 2013)
We may have mentioned this before, but we are in the process of making mbeddr an Eclipse project. We have been working on the proposal for a while, and it is now online at eclipse.org. So if you are interested in using or participating in the development of mbeddr, there will soon be a well-defined governance process. If you are interested in the project, why don't you register as an interested party for the project?
mbeddr Windows installer (28 Oct 2013)
After making it easier to use mbeddr on Debian-based Linux system, we are proud to announce that Windows users are now also able to use a simple installer to install mbeddr and all it's required tools. This will make using mbeddr on Windows much easier. The installer will run on any Windows system with .Net 4.0 installed. This is the case for Windows Vista and newer, or if you have manually installed it on XP.
The installer is available from now on with the install packages. After downloading it, you have to extract the zip file and run the mbeddr-installer.exe. It will ask you for administrator permissions and then download all the dependencies of mbeddr. We are able to download and install most of them but some need your interaction. The installer will guide you through the process. If you experience any problems with the installer please file an issue at our github repository. Beside a detailed description of the problem please also include the debug log of the installer. It is located in %TEMP%/mbeddr/.
The installer also deploys the mbeddr tutorial, in the subdirectory "tutorial". After opening it, you will likely get two errors. First, it complains about an undefined path variable mbeddr.github.core.home. Select Fix It, and delete the path variable. Second, it will complain about VCS root errors. Select Ignore, and the problem is solved. Both errors are a consequence of the fact that we take the tutorial from an environment that requires these two variables, it is currently not so simply to avoid the (easy to fix) errors in the deployed version.
New mbeddr Release (21 Oct 2013)
We have just created a new EAP release for mbeddr. You can get it at the download page. While we have called it an EAP, this is a fairly stable release that runs on the 3.0.1 version of JetBrains MPS. We are targetting a final 0.5 release for Eclipsecon next week. The code is probably ok, but we are struggling with updating the user guide in time. Keep the fingers crossed :-)
mbeddr Talk at EclipseCon Europe 2013 (21 Oct 2013)
From Oct. 29 to Oct. 31, the European edition of Eclipsecon will take place in Ludwigsburg, Germany. As usual it is packed full of interesting talks on topics around Eclipse -- and others! For example, there is a talk about mbeddr on Tuesday the 29th in the Bürgersaal room. In the talk, Stefan (from BMW Car IT) and Markus will talk about how mbeddr was used to simplify the development of AUTOSAR software. Of course, it includes an introduction to mbeddr itself as well. So if you are at Eclipsecon, please join us for the talk!

mbeddr debian package (04 Oct 2013)
Till today mbeddr was always released as a zip file that you had to unpack to your MPS installation. Which is fine on windows but since Linux systems ship with a powerfull package management system out of the the box, we are happy to announce that mbeddr is now also available as a Debian package. You can either download it from the Github release page or we have setup a repository containing the MPS and mbeddr package.
Customizing the Reporting Framework For Serial Output (17 Sep 2011)
Introduction
As some of you might already know I have worked on an Arduino extension for mbeddr. Because such systems run headless, you can't just use printf for displaying messages. These systems usually ship with a serial or USB port which can be used to communicate with the outside world. There are actually two ways to deal with this. First we could replace the printf-backing file handle with a handle that writes to the serial port. Second we can use mbeddr's own reporting infrastructure: this approach also gives us more flexibility because we could either write messages to the serial port or store critical errors in EPROM for further investigation.
Here I will talk about how to build your own reporting backend for mbeddr, in this case a backend that writes to the serial port.
Architecture
First I will give you an overview about the reporting architecture of mbeddr. It consists of four main parts: MessagesDefinition, MessageDefinitionTable, theReportStatement and a ReportingStrategy.
MessagesDefinition
Messages, as the name suggests, define messages. They have a name to reference them, a text that is written out when the message is reported and they may have parameters. These parameters are basically key-value pairs. A message also has additional attributes:
- MessageSeverity: similar to a priority it can be ERROR,WARN and INFO
- active: a boolean flag that defines if the message is active or not.
- count: a boolean flag that defines whether the number of times the messages was reported should be counted (useful in test cases).
MessageDefinitionTable
A collection of messages. Any MessagesDefinition belongs to a MessageDefinitionTable. It acts as a kind of namespace for messages.
ReportStatement
The ReportStatement is used to report a message. It references a message and provides the actual values for parameters, if the message defines any. The parameters can be any value matching the type of its definition, for instance a local variable or a value obtained from an external sensor. The statement also provides so called checks which is a guard. Only if it evaluates to true will the message be reported.
ReportingStrategy
The ReportingStrategy is used in the build configuration to configure which kind of reporting the project uses. In mbeddr there are already predefined reporting strategies: printf and nothing. As the name suggest the first one uses simple printf statements to report a message and the later does nothing with them.
Implementation
Now that we have a overview about what we need let's start implementing our own reporting.
ReportingStrategy
The first thing we need is a ReportingStrategy. To do so we create a new concept and name it SerialReportingStrategy:
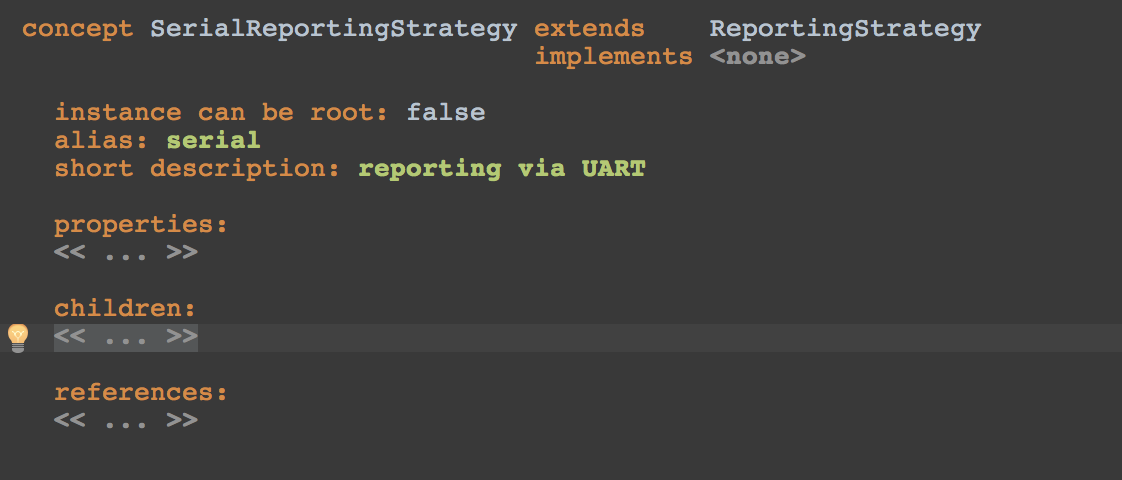
The editor also looks straight forward, just a constant cell with the words serial reporting in it:
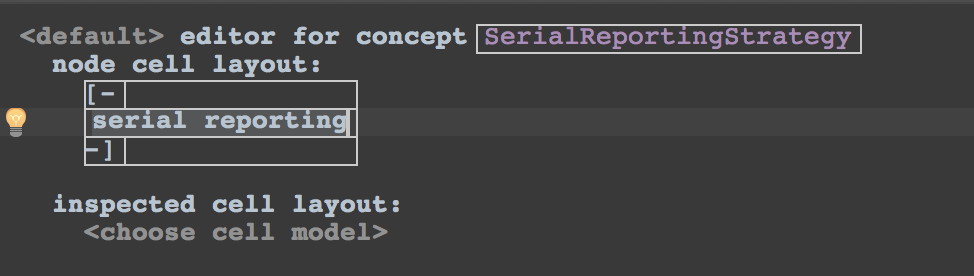
Now we can select this new strategy in the mbeddr build configuration:
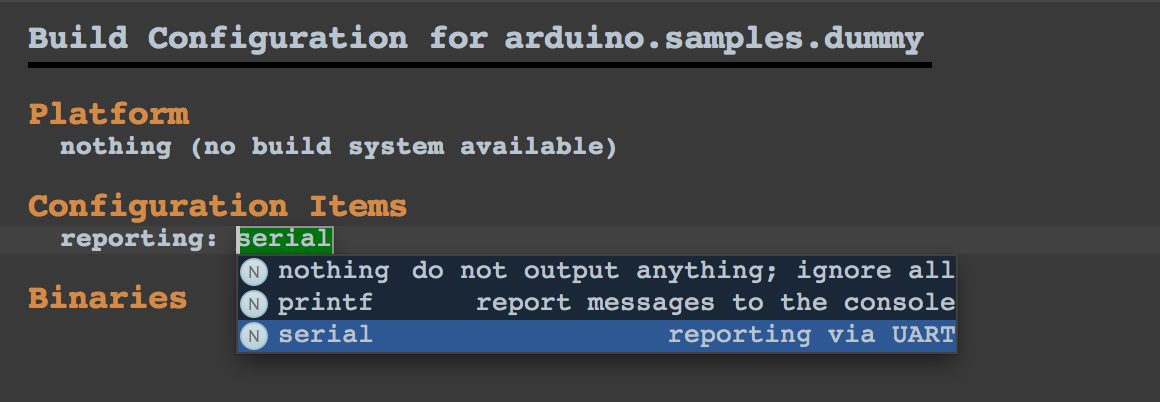
So thats it for the visible part. We can select it but it doesn't really do anything, because there is no generator that generates the code to write the serial port. To change this we need to add a generator that reduces the concepts discussed above to C, in case serial reporting is selected.
Generator
First we create a new Generator in MPS:
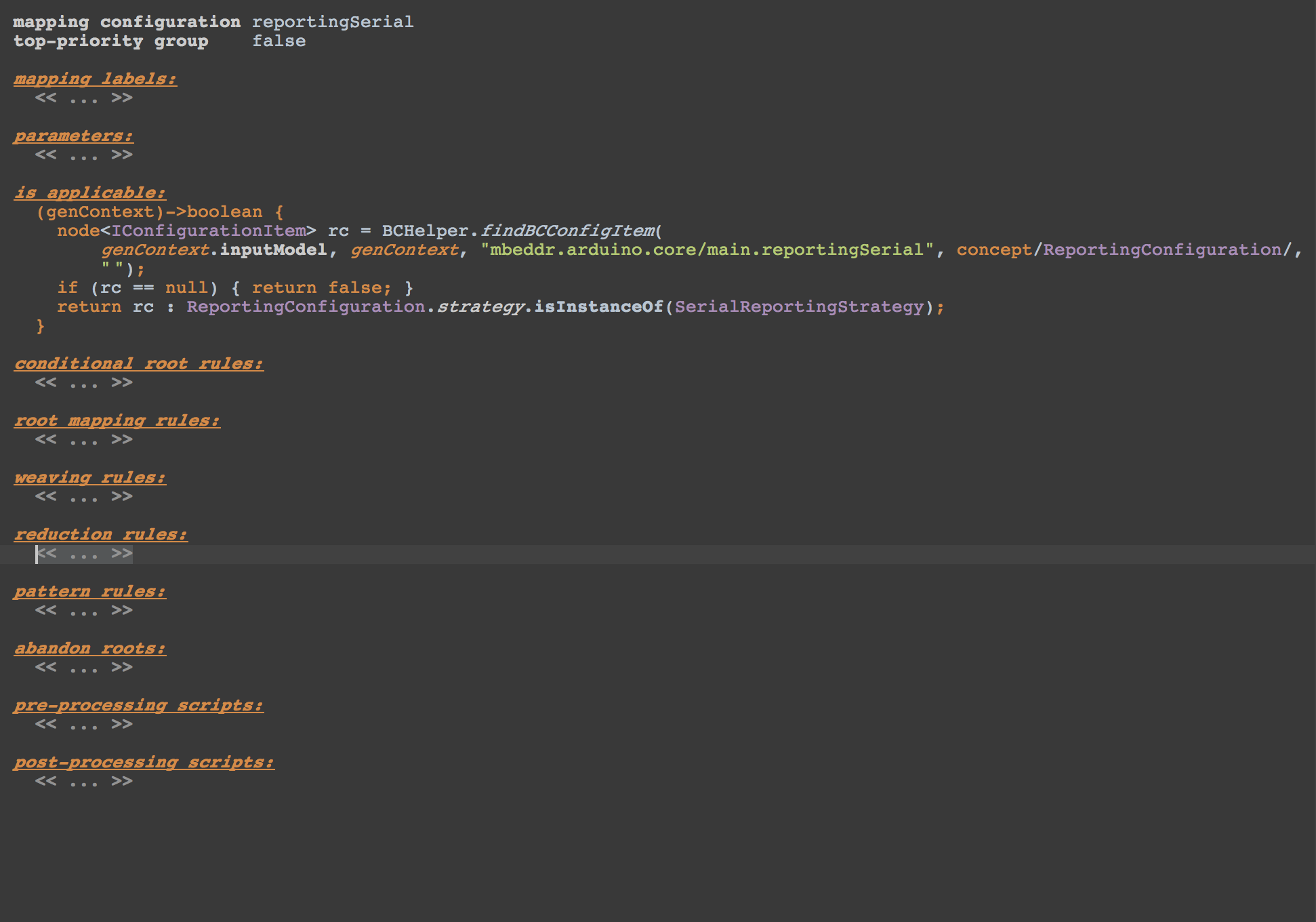
As you can see the is applicable rule checks if the selected reporting in the build configuration is the SerialReportingStrategy; otherwise this generator will not do anything (hoping that another generator will reduce the reporting concepts to C).
Let's start with the easiest thing the generator should handle: disabled messages! We create a reduction rule that only applies to messages that have the active flag set to false and then abandons the input:

The reporting architecture of mbeddr contains two core elements: a MessageDefinition and a MessageDefinitionTable which combines multiple messages. Messages are always part of a message definition table. So we need to reduce the table first. The generator is also quite simple. It take a MessageDefinitionTable and calls the $COPY_SRCL$ for its messages. Which loops over all of the massages and tries to reduce them in turn:

To get all the messages to reduce we use the nonEmptyMessages method of the MessageDefinitionTable behavior:

Next we need to reduce the message definition itself. We do two things in this reduction rule. First we generate a counter variable for the message. This variable can be used in tests to check how often a message occurred. In normal C code this variable is not relevant. And second we generate a char* variable that is initialized with the message text for later usage when the message is fired.1

The property macros for the names are quite simple, they just generate a unique name for each variable so that we can reference them later. The macro for the initializer of the string is a bit more interesting. It generates its value from the name of the message and the text but also appends a \n at the end for line ending.

Now that we have the texts and the counters generated, we can start with the part that emits the code to post the message to the serial port. I our case we have a library that does all the details. All we need to do is call a function with a char* as a argument. The library is added via the make file, the corresponding header file is called serial.h. So the next thing to do is reducing the ReportStatements, but in order to keep the generator clean we implemented two different reduction rules one for a message with parameters and one for messages without parameters. Later you will see why. Here is what the generator for messages without parameters looks like:
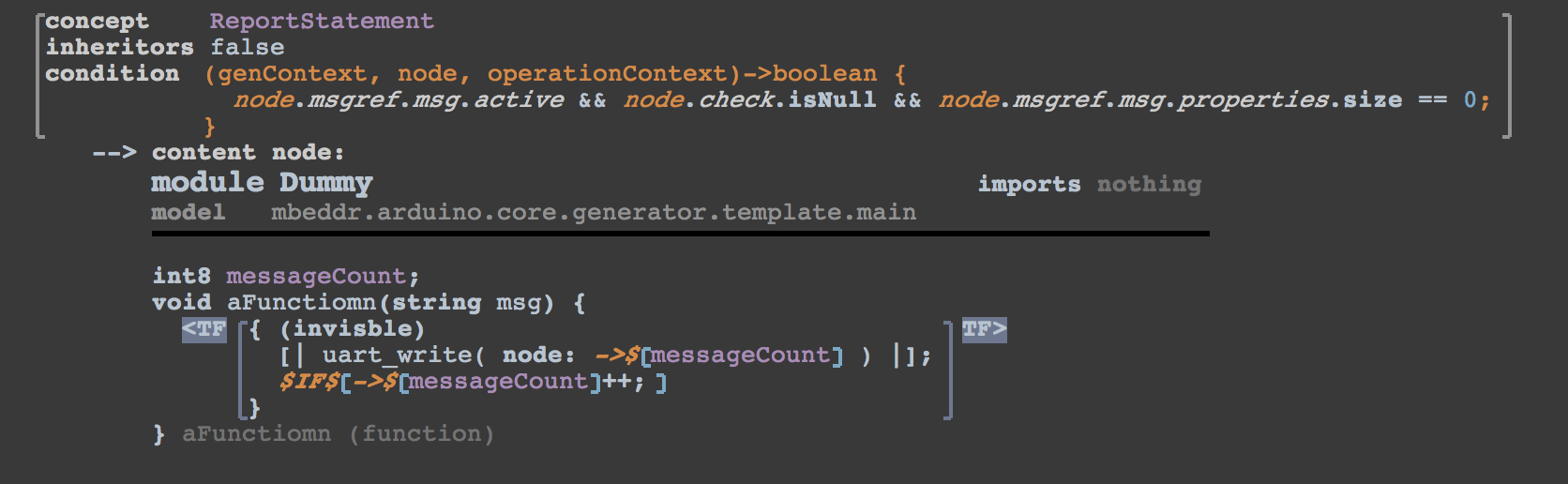
The condition checks if there are no arguments and it does not contain an check guard. The reduction rule then defines some dummy variable and a dummy function. Inside the function an ArbitraryTextExpression is used to insert some text which is not a expressed with mbeddr semantics. In the inspector you see that it also specifies a header to include and a type.
Both variables use reference macros, and the message counter is also guarded with an if in the generator to avoid emitting this code in the case the message is not counted.
Next is the ReportStatement with properties. It requires some more work to be done because we can not use printf we have to use sprintf and store that result in a buffer before we can put it to the serial port:
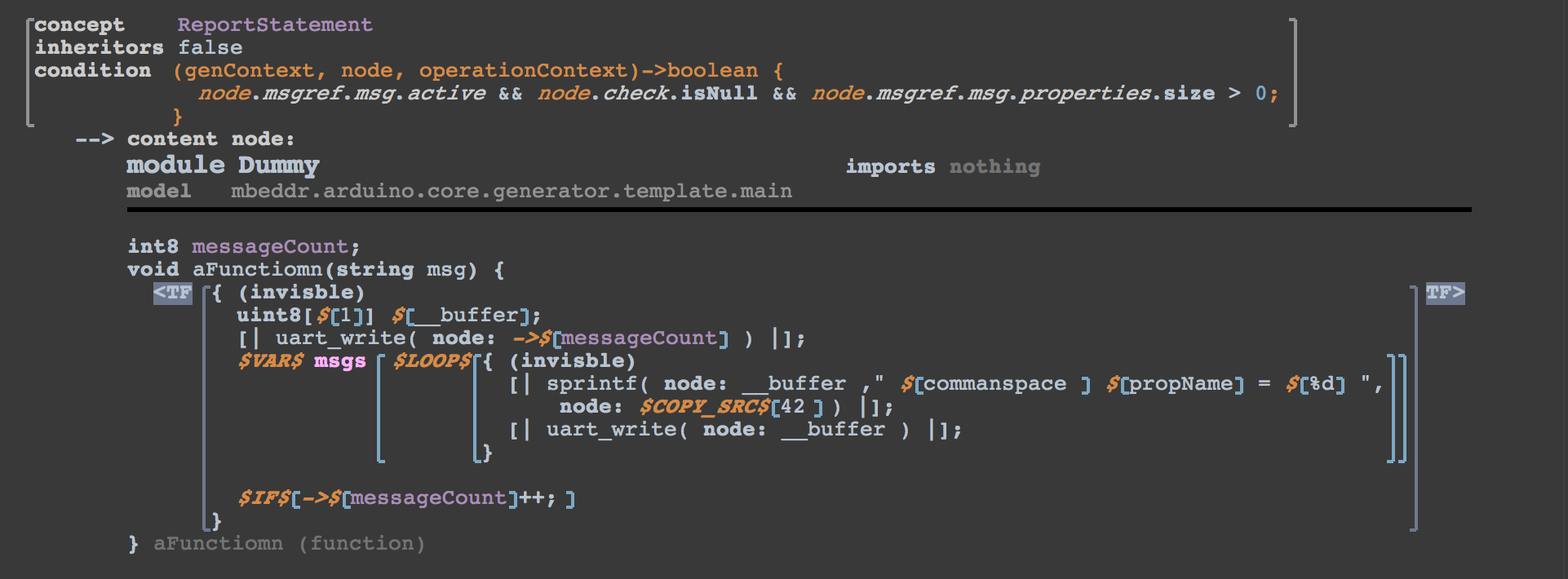
The major difference here is that it first generates a buffer variable to use it with sprintf, then prints the message and after that loops over all properties of the message where it prints them to the buffer and finally writes them to the serial port. The size of the buffer is also calculated in the reduction rule. It takes the maximum length of the property name and adds 24 to which is the maximum length of a 64 bit integer printed as a string plus the characters added to make it look pretty. There is downside of this hard coded number, it will cause long strings to be corrupted.
What's next?
As you may have noticed, the whole part of checks is missing. I omitted this because it would blow up the post and shouldn't be that hard to do for you if you are familiar with the generator. To prevent data corruption of long string parameters you can either prohibit the usage of anything else than a number as parameter by using a type system check rule or calculate the length at runtime. It's up to you!
The main part of this code was written while adding serial reporting support to the mbeddr.arduino project. You can have a look at the code there for further references.
-
Note: Due some limitations of older GCC versions char literals in C code would end up in the flash area of the memory which is a different address space. This is why the generator generates char* variables for each of messages. This done to either accomplish backward compatibility and to illustrate the difference between this generator and the printf generator. If I would have been lazy I could have simply copied the old generator and replaced the printf calls.
State Machines as Tables (09 Sept 2013)
The release of MPS 3.0 is imminent, and one of the new features of MPS 3.0 is the ability to have several independently defined editors for the same concepts. In addition, there is also a new add-on developed by Sascha Lisson that can do really nice tables. We have used these two features in mbeddr to support editing tables using a tabular notation. Take a look at this video:
New mbeddr Release: 0.5-EAP1 (22 Aug 2013)
On our github release page we have just released a new version of the mbeddr MPS plugins. This is the first release based on MPS 3.0 (see previous post on how to get it).
While we have been working with this state of the code on MPS 3.0 for weeks now and consider it stable, there may still be a few bugs as a consequence of the migration (hence the EAP: Early Access Preview). Also, we have not updated the user guide in a while, so it may not be correct in every detail.
We have scheduled time for working on the user guide later this year, and we are also working on more convenient versions of getting mbeddr. Among them an mbeddr-specific MPS build that contains all mbeddr-relevant plugins (and only those!) as well as a one-click installer (at least for Windows) that also installs all the necessary tools (cygwin, git, verifiers, etc.).
Stay tuned.
Migration to MPS 3.0 mostly finished (22 Aug 2013)
As you probably know, JetBrains has been working on a new major release of MPS, version 3.0. They are currently in the final phase of publishing release candidates and will release the final 3.0 in the next few weeks. Over the last few weeks, the mbeddr team has been working with EAP and RC versions of MPS 3.0 to move mbeddr to the new version.
We have been working with MPS 3.0 for a few weeks, and we think MPS and mbeddr are reasonably stable. We have since merged the 3.0 version into the mbeddr master branch. So if you update from github, you will get the version of mbeddr that runs on MPS 3.0. We will create a new release shortly.
So, to run mbeddr (from github), you will need MPS 3.0. You can get the current release candidate of MPS from the respective blog entries. Soon, of course, the final version will be available from the official MPS download page.
New Team Members (21 Aug 2013)
It's summer time, so people are on holiday, and we're progressing on mbeddr only relatively slowly currently. Also, we are mainly working for the big-secret-customer-project that is based on mbeddr. However, there's changes to our team.
First, we have a new team member, Kolja Dummann. In his professional life, he has worked for various companies in technical and enterprise software development. In his spare time, he has worked on the internals of Android in the CyanogenMod project. He has also developed an integration of mbeddr with Arduino: this is how we got in contact with him. As part of the mbeddr team, he is now working on the mbeddr RCP version and on a convenient installer. Stay tuned.
The second change in our team is that Domenik is now working for mbeddr full-time, since his master thesis is now finished. He continues to work on the debugger, the legacy code importer and the build server.
So as you can see, we are making progress, even though that progress is more in infrastructural aspects, and not so much on language extensions. However, these infrastructural aspects are just as important, and it is high time that we focus on those.
Migration to MPS 3.0 (30 Jul 2013)
Just a quick update from the mbeddr machine room: as you may know, the release of MPS 3.0 is just around the corner. It will have quite a few improvements in usability, one can add multiple editors for the same concept, and there will also be much improved table support. Over the last few weeks we have been on and off migrating mbeddr to MPS 3.0, and we are almost done. We are currently working on updating the build server. Once this is done, we are planning to create a new binary release of mbeddr, and we are also going to update the user guide to reflect the most recent version.
Zukunftsarchitekten-Podcast on mbeddr (16 Jul 2013)
In case you speak German, you may want to listen to the newest episode of the Zukunftsarchitekten-Podcast. It features a one-hour discussion with Markus on the problems with today's software development tools and how mbeddr can help address them. The podcast also looks at the somewhat bigger picture of systems engineering and how mbeddr can help solve some of the challenges in that space (such as requirements management and tracing).
Model-Checking State Machines with mbeddr (03 Jul 2013)
Christoph Rosenberger, a student of Peter Sommerlad's at the Institute for Software at the Hochschule Rapperswil has written a rather detailed article about model checking state machines with mbeddr. He discusses the theory of model checking, the implementation in NuSMV (the model checker used by mbeddr), as well as the user experience in mbeddr itself. Well worth a read!
The End of a Great Beginning (28 Jun 2013)
As you probably know, mbeddr has been developed in a government-funded research project called Language Workbenches for Embedded Software (LW-ES). This project has run now for two years now, and ends next week. From the perspective of the project partners, the project was a major success: we have managed to work together on a single tool, and hence produced something that is viable. Also, in particular fortiss and itemis have put in a lot more effort than what was strictly funded by the research project. Consequently, we are of course all sad to see this end.
However, the end of the research project is not at all the end of mbeddr. Quite the opposite, in fact. We see this merely as the end of the beginning. mbeddr will continue to be developed. mbeddr is used successfully in a growing number of real-world projects, clearly illustrating the benefits of the approach. We are also working on trying to get more research funding, to continue the research aspect of mbeddr (if you have ideas, please contact us :-)).
So: stay tuned, this site will continue to report on what's going on with mbeddr!
Improvements to the Requirements Language (26 Jun 2013)
We have made more improvements to the requirements language, and we've now started using it for project management and effort tracking. First, you can now specify work packages for requirements. A work package also contains an estimate of the effort needed to implement the work package. You can also define which team member is responsible. In addition, as the implementation progresses, you can register actual work hours and degree of completeness for work packages. Work packages can be marked as "seen by customer" and "accepted by customer".
To get an overview over the project, we supply several assessments. The most interesting one shows the work packages (optionally only for a given person and/or project milestone), and a little progress bar that reflects the implementation progress on the work package. The color of the progress bar changes to orange if the percentage of used effort is bigger than the percentage of work done ("bad trend") and it becomes red if the effort is bigger than the allocated effort. Finished ones become green. There is also a little traffic light that shows "seen by customer" as yellow and "accepted by customer" as green. It's red otherwise. Here is a screenshot:
Note how this "language" once again blurs the line between classical languages and more "application-like" things like forms or reports... (as a consequence of projectional editing!)
We are not positioning mbeddr as a standalone requirements engineering and project tracking tool (even though it is quite good at that). However, integrating these aspects into the tool makes a lot of sense for those teams that already use mbeddr for implementation. Combined with the existing support for tracing from example code to the requirements as well as for integrated design documents, mbeddr is rapidly shaping up to become a highly integrated environment for all aspects of embedded software development. In our current projects, we essentially never leave MPS/mbeddr.

Recent Developments (26 Jun 2013)
It has been quiet on the mbeddr blog for a while. We haven't implemented a lot of new stuff. This is for two main reasons. First, the release of MPS 3.0 is imminent, and we are in the progress of starting the migration. Many of the upcoming enhancements in usability will depend on 3.0, so we are holding off of implementing many new features currently.
More importantly, however, over the last 6 weeks we have been busy working with a customer on setting up the requirements for the project they want to run based on mbeddr. We will be working on this project for at least the next 6 months, hopefully much longer. This is a major (positive) development for mbeddr and we are all very excited about this opportunity. Stay tuned for more details -- we'll be sure to report them as soon as we can publicly talk about the project.
Business DSLs: Between Text, Models and Forms (04 Jun 2013)
mbeddr is of course targeted at technical users, people who develop embedded software based on C and mbeddr's C extensions. However, there are also aspects of mbeddr that are aimed at non-technical people. In particular, the requirements management support is clearly aimed at non-developers: all kinds of stakeholders who write requirements, or who add some formal business logic into requirements (mbeddr's requirements system is extensible in that way).
So how can you create DSLs and editors that are friendly to non-programmers? Many of these people are familiar with Word or DOORS as requirements management tools, so we should try to replicate the experience (while not adopting all the disadvantages of these tools).
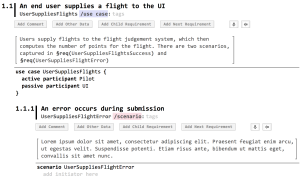
Over the last few days we have improved our requirements management language in this respect. Below is an example of the tutorial (demo) requirements:
Note how the model/program uses (relatively) nice formatting and a hierarchical structure for the requirements. However, within the text blocks, you can still use real (refactoring-safe) references, and the stuff below the line are formal models that can be checked and processed. One thing we've learned is that non-programmers often don't like IDE-like tools, but prefer buttons. So we've made the editor to optionally show buttons for the most important actions: add a new requirement, add a comment, move requirements up or down or make them a child of the previous sibling. The following screenshot shows the editor with helper buttons enabled:
Sometimes it is necessary to get a better overview over the requirements, and not be distracted by the details specified for each requirement. To enable this, we have created the Outline mode, where only the number, heading and tag of the requirements is shown. You can edit the details of the currently selected requirement in the inspector:
Notice how this rendering makes it look very familiar to non programmers, it provides some of the expected ways of editing things (buttons), but it still is highly structured (schema-driven) and formal parts can be added whenever needed. You also get diff/merge for free! We think this is a pretty great way to manage requirements!


Assessing your Program (03 Jun 2013)
MPS, like any other language workbench, supports various forms of constraint checks that lead to errors or warnings, annotated directly to the element that fails the constraint check. However, there are some kinds of checks that are different in nature: they may be global and require expensive algorithms to compute. They may be used to create some kind of overview, or report, and using error annotations spread all over the code may not be suitable. You may also want to mark failed constraints as ok and ignore them in the future. To support these use cases, we have added Assessments to mbeddr.
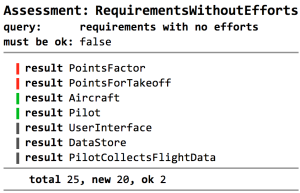
Here is an example assessment. It highlights all requirements in a model that have no effort specified. Not having an effort is a problem, and you may want to keep track of the requirements where you have yet to perform your estimation. The assessment shown below shows an example result (of course, the results are references and you can navigate to the offending requirement):
Note the colors. Green results are those that are marked as ok, so they are judged by the user to not be a real problem. Red results are those that have been added during the last update of the assessment. Black ones have been there from previous updates. Using the colors, you can keep track of the current state of the assessment, as well as of its changes. Assessment results are part of the model, so they are persisted and shared. They are intended to be actively maintained and managed (in contrast to regular error or warning annotations in the code). You can also set the "must be ok" flat to true, in which case the Assessment itself gets an error annotation if the results contain non-ok entries.
The requirements thing above is of course just an example and the assessment facility is extensible. You can define new queries/analyses, you can define arbitrary results structures and you can define arbitrary summaries (the one shown is the default and simply counts the entries).
We are currently using assessments in a customer project, where we use the facility to sum up the efforts for various project milestones and, at the same time, highlight those requirements as errors that have no effort specified. It has proven very useful.
System Running on its Target Device (31 May 2013)
About 8 months ago the itemis started the development of the first industrial application using mbeddr. When the software development started, no hardware was available as both were developed in parallel. While the embedded software uses nearly every aspect of mbeddr, components (including client server interfaces, sender receiver interfaces and composite components) have shown to be especially important. They enabled the software to be structured in a reusable and well-testable way. Due to that, most of the software can be tested on the development PC without the needing to have the target hardware at hand. Even components which require access to registers (for example, the display) can been tested on the developer’s PC, since register access can be simulated via a language extension. The components were also used to encapsulate those parts of the system that depend on a specific hardware platform, making the application logic hardware independent.
By the time the target hardware became available, the confidence in the software was quite high. However, the team did expected a few problems when they started to compile and download the program on the embedded microcontroller for the first time. The team therefore decided to perform a progressive integration in several steps to commission and test the different components of the software individually (e.g. watchdog, clock system, real-time clock, or display). It was literally a matter of hours to get the complete code working on the real hardware! Almost none of the problems were related to the implementation of the components. Most of them had to do with the setup and initialization of the microcontroller peripherals to get the target hardware into the right operating mode – something which cannot be tested on the development PC in advance. Very cool – and an experience to be repeated :-)
New Slides on mbeddr (almost) (29 May 2013)
Today Markus gave a keynote at SDA 2013 in Amsterdam called Generic Tools, Specific Languages. It proposed to reframe the problem of tool development and extension as a problem in language engineering and uses mbeddr as a (big) case in point. The talk also contained a demo of mbeddr, and the the slides at slideshare contain a current snapshot of almost all of mbeddr's most useful features. The mbeddr-specific stuff starts from slide 108.
Paper on Debugging (12 May 2013)
We've uploaded a new paper about Debugging: Language workbenches significantly reduce the effort for building extensible languages. However, they do not facilitate programmers with built-in debugging support for language extensions. This paper presents an extensible debugger architecture that enables debugging of language extensions. This is established by defining mappings between the base language and the language extensions. We show an implementation of our approach for the mbeddr language workbench.
mbeddr and Arduino (10 May 2013)
Kolja Dummann is working on an integration of mbeddr and Arduino. While his work is still work in progress, he has given a presentation about the current state today. Here are the slides, and the open source code is available on github.
An Empirical Study of MDSD and Embedded Software (and mbeddr) (26 Apr 2013)
(be careful, this is the longest post ever :-))
At MoDELS 2012, an interesting paper has been published: An Exploratory Study of Forces and Frictions a ecting Large-Scale Model-Driven Development by Adrian Kuhn, Gail Murphy and Albert Thompson. It present an empirical study on the problems that currently plague model-driven development in the industry. They have interviewed a number of developers from General Motors who use mainstream model-driven development tools (mostly Matlab/Simulink, IBM Rhapsody and MS Word for Requirements management) for embedded software development. The results are very interesting and worth discussing here, because mbeddr improves on all friction areas identified in the study.
Diffing: Diffing between various versions of the same model is insufficiently supported. Because of the fear to miss a change, developers have resorted to manually written comments that describe each change. Sometimes they even use a textual diff tool on the generated source. In some cases they create screenshots of a new version of a model, mark the changes with a red pen, and send the picture back to the owner of the model to incorporate the changes. When stating their requirements towards model diffing, they suggested that a facility like the diff support for code would be just what they needed.
mbeddr improves on this situation since any model or program can be diffed (and merged) with the diff and merge tooling provided by MPS. This works for any language, regardless of abstraction level and notation.
Point-to-Point Tracing: Traceability between implementation artifacts (model, code) and requirements is very important to all engineers interviewed in the study. The current tool-chain only provides document-to-document traceability, which is not granular enough. Traceability is required on the level of model or program elements, for any level of abstraction. Currently, the engineers rely on naming conventions and ticket IDs (as defined by their issue tracker) as a workaround. Since only very limited tool support is provided, this approach is tedious and error-prone.
mbeddr solves this problem completely by providing element-level traceability from arbitrary program elements to requirements or other high-level specifications. The traces are actual references and not just based on name equality. Tracing works for program elements expressed in any language, representing any abstraction level. Since all languages live inside the same language workbench, consistent tracing is much simpler than across a set of non-integrated (and often non-extensible) tools.
Problem-Specific Expressibility: The engineers interviewed in the study complained about the need for problem-specific expressibility, i.e. the ability to define their own "little languages" for particular abstractions relevant in the domain. The study cites two particular examples. One refers to the ability for domain experts to use concise visual notations when they describe requirements, and then generate code from the resulting diagrams. The other example identifies support for physical units as a major problem in the (Matlab-based) implementation models. They reverted to Hungarian notation to encode unit information into signal and variable names ("The printed list of all prefixes used in the system fills four pages").
mbeddr improves on this situation generally and specifically. The ability to extend existing language with domain-specific concepts allows end users to plug in their own "little languages" and generate abstractions available in the base language. Admittedly, mbeddr does not yet support graphical languages (as requested by the engineers in the study). However, it is safe to assume that the same kind of problems will arise with predefined textual languages. mbeddr also helps specifically with the two problems discussed in the study. mbeddr's requirements language can be extended with arbitrary domain-specific languages, and the models that become part of the requirements in this way can be used directly in the implementation of the final system. Also, mbeddr ships with a language extension for physical units that can be used with C or any of its other extensions.
Long Build Times: The engineers in the study report build times of the model-driven tool-chain in the range of several hours -- in contrast to ca. 30 minutes in the old, C-based tool-chain. These long build times prevent exploratory development of control algorithms, especially while in the car on the test track: whenever a change had to be made, the test drive had to be rescheduled for another day. Ideally, developers should be able to apply (certain kinds of) changes at runtime and continue the test drive immediately.
mbeddr does not provide an out-of-the-box solution for this problem, but it can help. To be able to change parts of a system on the fly, two approaches can be used (both suggested in the study). The first one relies on interpretation or data-driven development, where the behavior of a part of a system can be changed at runtime, for example, by changing the values of configuration parameters. To enable this approach, these configuration parameters have to be integrated with the hard-coded algorithm, and the constraints on the values of the parameters have to be described in a rigid way to prevent misconfiguration. Specific extensions of C (or other languages) can be developed with mbeddr, where the parameters and their constraints can be described succinctly, integrated with the hard-coded algorithm. Static consistency checking and IDE support is provided as well. This is much more robust than the ad-hoc XML-file based descriptions of configurability often found today.
The second approach for improving turn-around times mentioned in the study is hot-swapping of code generated in the field. To make this possible, the underlying system must be partitioned well, and the interfaces between different program parts must be clearly defined. mbeddr's interfaces and components, plus a suitable DSL for defining the partitioning of the target binary, can help solve this problem. Note that better modularity and clearer interfaces reduce build times in general, since there is no need to regenerate the whole system when a part changes. Together with mbeddr's support for testing and mocking, this can improve testability. Taken together, these two approaches can significantly reduce turn-around times during the development phase.
Graphical Notations: The paper does not identify the graphical notations provided by the mainstream tools used by the engineers as a friction. However, the paper does point out a set of problems with graphical notations (the paper points out that these problems apply to the notations and tools used in the study, may not be generalizable to graphical notations in general) and the limited set of abstractions provided by the modeling tools (such as scopes or subroutines). Another problem is reported to be the fact that diagrams have no obvious reading direction, which is compensated by modeling guidelines. Developers report to be struggling with reading visual models, to make sure they do not miss important parts. The paper states that,
[..] when offered an alternative to visual programming, engineers seem to prefer non-visual representations.
In the available tools these were forms and tree views. It is reasonable to assume that, if textual notations had been available, these would have been preferred over trees and forms, since the developers express that they miss "programming" in other parts of the paper. The discussion of the visual notations provided by the tools used in the study also points out the following:
While this language is visual, it does not seem be an actual abstraction from source code. Even worse, as we learned through our interviews, the level of abstraction seems to be lower than high-level source code. For example, engineers reported that they struggle to introduce abstraction such as nested scopes of variable visibility, enumerators, or refactoring duplicated code into a new method.
mbeddr takes a fundamentally different approach. First, it uses textual, symbolic and tabular notations. Second, since it starts out from C, existing C abstraction mechanisms such as the nested scopes of variable visibility or enumerators are supported. The IDE supports various refactorings. Third, additional domain-specific abstractions can be added at any time, in a modular way.
Summing up, the paper draws a rather bleak picture of today's mainstream use of model-driven development in embedded software (and our experience is certainly in line with this picture). mbeddr improves on several of the problems discussed in the paper and our preliminary experience with mbeddr confirms this.
Eclipsecon France Session (25 Apr 2013)
It has been quiet here on the blog, we are busy improving the stability of mbeddr and using it in the smart meter and other projects. We've also presented mbeddr at JAX and at the MBEES 2013 Dagstuhl workshop this week.
More recently, a session about mbeddr has been accepted for Eclipsecon France. Bernd will present it.
The session is part of the Cool Stuff track -- I guess that's a fitting choice :-)
A Paper on Requirements Management in mbeddr (04 Apr 2013)
We just added a new paper to the learn page. It discusses mbeddr's approach to requirements management. We discuss requirements themselves, paritial formalization of requirements using DSLs embedded in requirements, CRC-card-like high-level architectures and tracing from implementation artifacts to requirements and other "trace targets".
The paper has just been accepted at the Dagstuhl 2013 MBEES Workshop.
New Virtual Box Image (28 Mar 2013)
Just before easter, we have released a new virtual box image with all of mbeddr on it. You can get it from the download page. Have fun, and happy easter!
A new Distribution (22 Mar 2013)
We have just published a new distribution. It contains all kinds of bug fixes, of course. In addition, we have since merged the richtext/multiline support to the master. So this distribution contains the improved comments as well as the documentation language.
Documentation of the Documentation Language (18 Mar 2013)
A while ago we reported on mixed content editing in MPS, and how we have built a documentation language that can mix prose text with actual program nodes. We have now merged this code onto the master branch; it is also used in our requirements management language as well as in our code comments. To explain how it works, we have also extended the user guide. The respective part of the user guide can be downloaded separately. Note that this document is of course written with the documentation language itself, so it is able to bootstrap itself. There are still a few bugs which whitespace, line breaks and selection, but these will be fixed in due course.
All in all, this is a very significant enhancement for mbeddr -- not so much in terms of coding of course, but in terms of being able to build an overall software engineering environment.
SoftwareArchitekTOUR Podcast on mbeddr (11 Mar 2013)
If you speak (or rather, understand) German, you may want to listen to this newest episode of the SoftwareArchitekTOUR podcast. If you have followed mbeddr, then there's probably not too much news in the episode. But it's probably a good introduction -- which you maybe want to pass on to coworkers who haven't spent time with mbeddr yet.
Workshop Paper Accepted at NASA Formal Methods Symposium (11 Mar 2013)
We recently got out paper Using Language Engineering to Lift Languages and Analyses at the Domain Level accepted at the NASA Formal Methods Symposium 2013. In the paper, we mainly discuss how we integrate the static checking of pre- and postconditions as well as protocol checking (based on C-level model checking) into mbeddr. Download the paper here.
Tech Preview: Mixed Content Editing (07 Mar 2013)
Here is something really cool we're currently working on: mixed content editing in mbeddr. What does mixed content mean? It means that you can mix prose (i.e. free text, with text-editing-feel) and actual MPS program nodes (with code completion, referencing, refactoring). As a proof of concept, we have built a really nice documentation language that can deal with images, visualization, code references and embedded code snippets -- generating to HTML and Latex. We also show how to integrate expressions with prose text.
The whole thing is based on Sascha Lisson's Richtext editing facility (https://github.com/slisson/mps-richtext/). While this stuff is not yet quite finished and not yet on the master branch, it's extremely cool and definitely worth showing now :-)
mbeddr @ embedded world 2013 (26 Feb 2013)
It is almost a tradition now ... once again, mbeddr is presented at embedded world 2013, the world's largest conference and exhibition on embedded systems and embedded software. Of course, mbeddr is demo'ed at the itemis booth (4-106), where mbeddr is shown based on two example applications.
One is the smart meter project, which itemis France is working on. The other example is a synthesizer that is implemented completely in mbeddr, built by our colleague Aykut Kilic.
In addition, Bernd will have a presentation called Embedded Software Development for the Next Decade on Wednesday 11:00 - 11:45, Session 09, High-Level Languages, where he will show, among othe things, the improvements in the area of requirements.
In case you are at embedded world, why don't you say hello to Bernd and have him demo our newest enhancements in mbeddr?


New Download Option: VirtualBox Image (24 Feb 2013)
We have just created a new way of trying out mbeddr: a completely preconfigured VirtualBox Ubuntu image that contains MPS, mbeddr, gcc, gdb, and all of the verification tools. It is a 3GB download, so you do trade pain-free installation for download time :-) Please see the redesigned download page for details.
How to learn MPS (24 Feb 2013)
We often hear that the documentation for MPS is bad, and so it is hard or impossible to learn MPS. Granted, MPS has a somewhat steeper learning curve than some other DSLs tools, but on the other hand it is also much more comprehensive than many others: for example, it supports declarative type systems, dataflow analysis, language composition and domain-specific debugging. And granted also, any documentation can always be better, and there is always some point at which you won't find a problem solved by reading docs. In this case you can always ask questions in the MPS forum or the mbeddr mailing list.
We think, however, that the available documentation for learning MPS is actually quite good. So let's take a somewhat closer look.
To get started, and to get an initial idea of how MPS works, we suggest you take a look at two screencasts from Vaclav Pech at JetBrains TV (screencast 1, screencast 2).
Then, to get an overview over all the different language aspects and how they fit together, we suggest you take a look at the DSL Engineering book. In Part III on DSL implementation it contains a lot of examples with MPS. The book is available as a PDF (donationware), so it's easy to obtain.
Next, we suggest you grab the mbeddr user guide and read the tutorials on language extension. It describes in quite some detail 10 different extensions to the C language in MPS.
If that is not enough, there is of course a lot of additional documentation available at the MPS docs page. It contains many screencasts and written tutorials. Some of them are a bit outdated, but they still help convey the fundamentals of how MPS works.
A New Case Study: ASIC Testing (22 Feb 2013)
The Learn page has just been updated with a new case study on ASIC Testing. This case study describes how Daniel Stieger from die modellwerkstatt and Michael Gau from Bachmann electronics built a DSL and a C generator for testing ASICs.
New Screencasts (17 Feb 2013)
In preparation for the Embedded World 2013 conference, where mbeddr will be featured on itemis and fortiss booths, we have started creating a few screencasts. Stay tuned, there will be more coming in the next few days.
Visualizations Reloaded! (14 Feb 2013)
We recently added new visualizations to mbeddr. These new visualizations are based on PlantUML, a textual language for describing UML diagrams, plus a renderer that generates the diagram itself (partially based on Graphviz). We've built our own SVG-based viewer, integrated into MPS, so we can use click-to-go-to-editor from within the picture. It is easy to build custom visualizations simply by implementing an interface and overriding a method that generates the PlantUML input text. The rest is automated.
PlantUML is highly recommended: works well, easy to use, and when we encountered a problem, we got a reply to our question quickly, and within a few days, there was a new version that fixed the problem. In other words: PlantUML is actively maintained and the community is alive!
Importing Legacy C code into mbeddr (13 Feb 2013)
Our colleague Federico Tomassetti has spent the last few months working on a facility that can import existing textual C sources into mbeddr. The challenge, of course, is to handle the preprocessor correctly. Federico has done various studies of how the preprocessor is used (see, for example, this paper). Based on these studies he has made significant progress with a preprocessor-aware importer. Today, Federico has recorded a screencast that shows the approach and the current status. The video is embedded below. For details you might also want to take a look at a related blog post.
mbeddr featured in Markus' DSL book (26 Jan 2013)
Markus has recently published his new DSL book. This is relevant for mbeddr in several ways: first, mbeddr is used as a case study in the design part of the book as well as in part IV, which addresses the use of DSLs. Second, the book contains some detail on how to develop languages with MPS. And third, it provides a general introduction to DSLs and modular languages -- which is of course central to mbeddr. The book is available in print as well as a donationware PDF. Check it out at dslbook.org.

Sender/Receiver Interfaces Added (16 Jan 2013)
We have added sender/receiver interfaces to components. So far, we only had client/server interfaces, which define a set of operations (with contracts) that can be called by clients. Sender/Receiver interfaces are different in that they simply define data items that are exchanged by components. While this sounds like global variables, it is not: the component instances and their sender/receiver ports still have to be wired up. Also, this kind of interface makes most sense for a system that employs some kind of middleware (although you can of course use them in a non-middleware setting).
In fact, we have built these sender/receiver interfaces in anticipation of the BMW Car IT case study that has started recently, where we will soon be building an integration of the AUTOSAR RTE with the mbeddr components language.
mbeddr Paper accepted for AUSE Journal (16 Jan 2013)
We've just been notified that our paper mbeddr: Instantiating a Language Workbench in the Embedded Software Domain has been finally accepted to the Special Issue Innovative ASE Tools of the Journal of Automated Software Engineering. This is the most comprehensive paper on mbeddr so far, 50 pages! We'll publish a paper draft later, here is the abstract:
Tools can boost software developer productivity, but building custom tools is prohibitively expensive, especially for small organizations. For example, embedded programmers often have to use low-level C with limited IDE support, and integrated into an off-the-shelf tool chain in an ad-hoc way. To address these challenges, we have built mbeddr, an extensible language and IDE for embedded software development based on C. mbeddr is a large-scale instantiation of the Jetbrains MPS language workbench. Exploiting its capabilities for language modularization and composition, projectional editing and multi-stage transformation, mbeddr is an open and modular framework that lets third parties add extensions to C with minimal effort and without invasive changes. End users can combine extensions in programs as needed. To illustrate the approach, in this paper we discuss mbeddr's support for state machines, components, decision tables, requirements tracing, product line variability and program verification and outline their implementation. We also present our experience with building mbeddr, which shows that relying on language workbenches dramatically reduces the effort of building customized, modular and extensible languages and IDEs to the point where this is affordable by small organizations. Finally, we report on the experience of using mbeddr in a commercial project, which illustrates the benefits to end users.
C++ Update (16 Jan 2013)
We've discussed the possibility of implementing C++ in mbeddr before. We are now making concrete progress on this front. We will get a very competent Masters Student in about a month who will work on C++ full time. He has significant real-world experience C++ (incl. templates and template meta programming). We may also have a customer coming up who will need to be able to generate C++ code, including templates. Hence we have started working on a prototype, and basic classes and object, as well as basic templates already work.
We are also looking to get other people involved in the effort. Are you interested? Please let us know!.
Recent Updates (21 Dec 2012)
The progress in mbeddr these days is mostly in details. We work a lot on robustness and fixing bugs. However, we have added one major new feature recently: hierarchical state machines. This means that you can now have composite states which contain their own set of states. Transitions defined on the composite state are applicable to the contained states, and entry and exit actions are handled correctly. Below is a screenshot of the tutorial state machine refactored to use composite states:
Also, JetBrains have just shipped version 2.5.3 of MPS which also contains a set of bug fixes relevant for mbeddr.
So as you can see, things are moving. Stay tuned for next year :-)

Top-Down Programming (08 Dec 2012)
A problem with projectional editors is that they can only construct structurally correct programs. While is is of course a Good Thing in principle, it also means that each program must be structurally correct at any time. This has one particular disadvantage: you cannot enter a reference to something that does not yet exist.
For example, if you write the implementation of a function and you notice that you want to call another function (that does not yet exist), you first have to move into the module and create the function (possibly, of course, without the implementation). Only then can you enter the call to that function. This is annoying.
To address this issue, we have now implemented a number of intentions: if you enter something that cannot be bound (i.e. the cell remains red) you can use an intention to create various things, depending on context: local variables, global variables, functions, and arguments, but also component fields or state machine states. This leads to a much more fluent editing experience.
Small change, big effect :-)
Tutorials on Language Extension (21 Nov 2012)
We have added another ca. 100 pages to the mbeddr User Guide. In this most recent iteration, we have added tutorials on how to build 8 different language extensions. Each of the tutorials focusses on a different way of extending mbeddr C, or of contributing additional DSLs to the system as a whole. The tutorial project also ships with the full source code for all of these languages, and with example uses.
This latest round of enhancements enables mbeddr users to learn how to add their own abstractions to the mbeddr ecosystem. While we assume some basic familiarity with MPS language definition techniques (which you may acquire from reading the MPS documentation), we do explain things in quite some detail.
New Example Code and Tutorial (07 Nov 2012)
Over the last two weeks we have worked on a new, comprehensive example for mbeddr. The example, which is available from the download page, illustrates most of mbeddr's C extensions (not in every detail, but you can get a good impression of mbeddr). We have also documented this example system extensively: the user guide (available from the download page as well) now has 50 additional pages that contain an extensive tutorial.
Together with the new plugin-based build we published last week, this should make mbeddr much more accessible.
Important Milestone: mbeddr as MPS plugins (29 Oct 2012)
Today we have finally managed to have our build server automatically build MPS plugins for mbeddr. All of these plugins are in the new binary archive provided on the download page. To install mbeddr, simply copy the contents of the ZIP's plugins folder into MPS' own plugins folder. No more setting path variables, etc :-)
Another Case Study Uploaded (29 Oct 2012)
We have just uploaded another case study: Lego Mindstorms. This case study is the original demo we built with mbeddr. Although a Lego Mindstorms robot seems like a joke, the case study uses the OSEK operating system and contains interesting C extensions for OSEK.
First Case Study Uploaded (03 Oct 2012)
As we had mentioned in the previous post, we are in the process of building real-world applications with mbeddr. To document our experience and showcase what mbeddr can be used for, we will publish case studies (of various sizes and levels of detail) on the website (on the Learn More page). We start with the Smart Meter case study mentioned earlier. It has just been uploaded.
mbeddr used in first real-world project (01 Oct 2012)
It has been quiet here over the last few months. Of course, it was summer so everybody slowed down a bit. Another reason, however, is also that we have been busy ramping up the first real-world commercial project with mbeddr. The project is a Smart Meter system developed by itemis france.
A smart meter is an electrical meter that continuously records the consumption of electrical power and sends the data back to the utility provider for monitoring and billing. The software comprises ca. 30.000 lines of mbeddr code. Several of the mbeddr default extensions are used, and additional, project-specific extensions have been developed. Three developers are involved in the project at this time, including people from the core mbeddr team as well as outsiders.
Stay tuned for a more detailed case study in the near future.
Best Paper Award :-) (01 Oct 2012)
At the Modevva 2012 workshop the mbeddr team has won the Best Paper Award and the Best Presentation Award with our contribution Implementing Modular Domain Specific Languages and Analyses. The paper discusses how we exploit language engineering to efficiently develop formal analyses. Congrats especially to Zaur Molotnikov who did the actual presentation :-)
Video: mbeddr session from Code Generation 2012 (23 Jul 2012)
At the CodeGeneration 2012 conference there was a session on mbeddr, and the folks from InfoQ recorded a video which they have released now. I guess the video can serve as a good overview over mbeddr, even though the camera seemed to have a hard time keeping the live coding in focus --- it is hard to read. Give it a try :-)
mbeddr bei heise developer (21 Jul 2012)
heise developer has published a short (German) article about mbeddr that summarizes the idea and provides an overview over the approach.
If you read this blog, there's probably nothing new in the article, but it might be something you might want to forward to people who haven't heard anything about mbeddr yet?
New Download Packages (14 Jul 2012)
We have just uploaded new distribution packages for you to download. The build number has increased from 3xx to 733 - so a lot has changed and improved. The system is of course not yet finished or free of bugs (see the open issues), but by working with mbeddr in a real, non-trivial application project, many issues have shown up and have been fixed. Most importantly, this version works with MPS 2.5, so please make sure you download it first.
Productivity Tools (12 Jul 2012)
As you may know, we are currently in the process of building our first real-world, non-trivial application based on mbeddr. In this process we are of course finding and fixing all kinds of bugs. However, we also find more general productivity issues. For example, it is tedious and error prone to find the source of an assertion failed message in our test output. Sure, the output specifies the module/function/assert that failed, but it is still annoying.
To solve this problem we have created a new view, the mbeddr Error Output Analyzer. You paste the console output of a set of tests into a textarea. The view then parses the output and searches for the nodes that created the messages in the output. It lists the nodes in the view so you can then click on the node to select it in the editor:
We have created a similar view that finds TODOs in comments.

mbeddr and MPS Tutorials this Fall (10 Jul 2012)
This fall there will be several chances to take a closer look at mbeddr and MPS. As it looks now, at least the following three tutorials will take place.
On September 3 we will run a Full Day Tutorial at MATHEMA's Herbstcampus in Erlangen. It is called Massgeschneidert - Language Engineering mit MPS and will focus on MPS' in general.
On October 2 we will do a Half-Day Tutorial at MoDELS 2012 in Innsbruck. It is called Language Workbenches, Embedded Software and Formal Verification, so this is quite mbeddr-specific.
A Full Day Tutorial will take place on Monday, November 5, at W-JAX in Munich. It is called Make this YOUR Java, and we will focus mostly on Java extensions. But of course the mechanisms are the same as for C...
So if you want to learn more about mbeddr and MPS you may want to join us...
MPS 2.5 and mbeddr (04 Jul 2012)
A few hours ago, JetBrains have published MPS 2.5 (see here for what's new). Over the last weeks we have been working on migrating mbeddr to MPS 2.5, so the code on the master branch is already on MPS 2.5. We will create a new downloadable ZIP file over the next few days.
A Sign of Life (12 Jun 2012)
It has been quiet here on the blog recently. This is for the following reasons. First, we have been using mbeddr in a first application project. So we haven't evolved mbeddr much, but instead used it in a real project. As a side effect, we have worked a lot on the importer for existing header files. Contact with the real world was painful there :-)
In addition, we are currently in the process of migrating to MPS 2.5, which is currently in the release phase. We have finished most of the migration of the github repository to MPS 2.5 RC1. We're also happily reporting bugs and issues to the MPS development team at JetBrains. So at this point, if you want to work with mbeddr, we suggest you use the download ZIPs or the code from the beforeMigrationTo25 tag until we have finished the migration completely.
All-in-One ZIP File Download Available (02 Max 2012)
We have changed our download to just one big ZIP file that contains everything. This makes downloading simpler, and also avoids incompatibility problems among different parts of the system downloaded at different times/versions. Get the ZIP here. We have also consolidated the documentation into a user guide (for everything) and an extension guide. These are in the ZIP, and also available separately. We still have to update the documentation and add some more "meat". We hope to be able to do this in May.
Have fun and let us know what you think!
Components, State Machines, Exceptions, Units: All Open Source Now (28 Apr 2012)
We have recently moved the code for the components, state machines, exceptions and physical units to the github repository. At this point only the formal methods package is not yet open sourced, but will be by summer 2012.
We are still in the process of finalizing the download packages and the documentation for these features, so stay tuned :-)
Status of the Header File Import (20 Apr 2012)
We have always said that we will provide an automatic import for existing C header files so you can call into 3rd party libraries. We have now finished the importer to the point where it can import structs, typedefs and function signatures --- in effect, all the regular C stuff.
However, C header files can contain all kinds of weirdnesses: macro definitions, macro definitions being called from within the same header, #defines that use expressions, non-volatile memory layout definitions and of course #ifdefs. These turn out to be non-trivial to handle. However, we think we have found reasonable ways of addressing all of them and we are confident we'll have a working solution within weeks.
In fact, we are currently in the process of starting the first real-world application projects with mbeddr, and the headers used in these projects drive the implementation of the importer. We aren't quite there yet, but we are making good progress.
First Cut at Physical Units (25 Mar 2012)
Recently we have implemented the first version of physical units. This is an important aspect in embedded systems and comprises an enhanced type checker plus some tweaks to the code generator (as of now, we only implemented the type checking). The feature consists of two parts. First, we have implemented the seven SI base units as built-in types. We have then created a facility for users to define arbitrary derived units. The following screenshot shows an example.
These types, as well as the SI base units can then be used to annotate types and literals as shown in the next screenshot. We have implemented a restriction that allows only numeric types and the corresponding literals to be annotated with units. Note how the type checker performs unit computations for multiplication and division and reports errors if you try to add "apples and oranges".
What makes this feature remarkable is this: no change to the C base language was necessary. Everything described above is completely additive and packaged into a separate language module that can be used in programs optionally. Also, the total effort was under two days!
Once again, this brought smiles to Bernd's and Markus' faces: MPS really is a terrific tool for language engineering!


An simple Product Engine based on mbeddr (22 Mar 2012)
Over the last one and a half days we have built a little demo of DSLs for the insurance domain. It is based on mbeddr and shows nicely how extensible the whole system is. The example is a simple product modeler, including a way to test the calculation formulae directly in the IDE via a table and an interpreter (click on the screenshot to show a bigger version).
The example also shows nicely the benefits of using non-textual notations (tables in this case). We were able to integrate requirements traces and product line variability without any changes --- validating the orthogonality of the approach. While we use C's expression language in the insurance calculations, we exploit MPS' constraints to limit the set of possible expressions to those that make sense in this domain (i.e. removing some of the C-specific ones such as the address-of operator or the dereferencing operator).
All in all, this was a nice validation of mbeddr's extensibility and the capabilities of MPS.

Requirements and Variability Support Open Sourced (22 Mar 2012)
Today we have open sourced the next set of extensions: the support for requirements, tracability and product line variability. We have packaged all of this into a single distribution file available from our new github download page, and of course you can find the code in the repository. You may want to take a look at the documentation PDF that explains the requirements, traceing and PLE support.

mbeddr @ Embedded World, Part II (02 Mar 2012)
The Embedded World 2012 conference is over. As we had mentioned before, mbeddr was shown at the itemis booth as well as in a talk.
There was considerable interest in mbeddr (and the other itemis offerings; not all the people on the photo above were at the booth because of mbeddr :-)). Bernd did a great job of spending three long days at the conference, convincing people that the "somewhat different" mbeddr approach is worth considering.
The feedback and interest we received is a good basis for mbeddr prototyping over the summer.
Formal Analyses in mbeddr (02 Mar 2012)
We have blogged about the use of formal verification and analyses methods in mbeddr before. We have now published a relatively detailed technical report that explains the philosophy of formal analyses in mbeddr. Take a look the the Learn More page.
Dog Food - Extending MPS itself (25 Feb 2012)
MPS provides a set of DSLs for defining DSLs. They DSLs are all extensions of a common base language called BaseLanguage :-), which is essentially Java. So in the same sense as mbeddr modularly extends C to enable embedded development, MPS modularly extends Java for efficiently defining DSLs.
And in the same way as mbeddr can be extended by users, MPS itself can be extended by users. MPS it built with itself (bootstrapped), so extending the MPS BaseLanguage is not different from extending any other language. Recently we have exploited this to build DSLs that make the implementation of our DSLs simpler. In this post we want to show a few examples (click on the code for bigger fonts).
The first example is a new expression that forms the basis for quickly writing model interpreters. It is called the dispatch expression. It takes an expression as an argument, and each case referes to a language concept. The right side of the case is executed if the expression is an instance of the language concept referenced on the left side of the case. What makes this expression so convenient is that there are two special, additional expressions that can be used on the right side of the arrow. The it expression refers to the expression passed into dispatch, but it is already downcast to the respective language concept. The # expression recursively calls the function in which the current dispatch resides. As you can see from the example code above, this makes for very compact interpreter code.
The second example is an extension of BaseLanguage that is used in defining the debug behavior for language extensions. As you can see in the getStepOverStrategy method above, the new statements can be used inside regular concept behavior methods. In fact, these new statements are restricted to be used only inside a few methods of the ISteppableContext interface, because they only make sense there. Using these statements, the definition of debug behavior can be done much more concisely.
The last example is the well-known builder. It supports construction of MPS "model trees" with a very convenient syntax. Note that this is a real language extension, not something built with closures and other meta programming facilities. As a consequence, the builder works with arbitrary structures (as long as they are MPS languages), it understands the structure of the to-be-built tree and provides code completion and static error checking regarding the structural correctness of the created tree.
Summing up, it is extremely useful to be able to extend the infrastructure you're working with --- it makes working with your own abstraction during language definition much simper. And the fact that MPS can be extended in the same way you use for extending other languages is just plain cool :-)



The mbeddr Debugger (21 Feb 2012)
The debugger for mbeddr is making good progress. We can essentially debug all of C, and we have proof-of-concepts for debugging state machines and components. The screenshot below (click to see full size) shows an example debug session for components.
MPS comes with a framework for building debuggers. However, this is relatively low-level and we have added a set of abstractions on top of it. This includes simple ways of defining the debugging behavior for custom language concepts. We are still in the process of cleaning up the API, but we are very happy with the progress.
The debugger is already part of the open sourced code, but we still haven't described in the documentation how to set up MPS so that the debugger works --- we need some additional libraries. We hope to do this in the next month. Stay tuned :-)

mbeddr.core code is at github! (18 Feb 2012)
We have finally gotten around to publishing the core code on github. It contains C, the unit test extension, the build support as well as the debugger, the user guide and the extension guide. We have also published or MPS utilities project, which contains MPS languages for outlines and graphs, as well as the graphviewer we discussed in a previous post. The repository is at
http://github.com/mbeddr
As of now, only our project team are registered as committers. However, you can always clone the repository, make changes there and then send a pull request to us so we can get at your code. And of course, once you've contributed useful patches, we may make you a committer. More parts of the mbeddr technology stack will follow.
mbeddr @ Embedded World (17 Feb 2012)
mbeddr will be present at this year's Embedded World exhibition and conference from Feb 28 to March 1. You can find mbeddr at the itemis booth in hall 4, booth 408. Bernd and Markus will be there. mbeddr was also accepted into the conference program, so on Thursday at 16:30, in Session 13, Bernd and Markus will present mbeddr. So if you want to see a live demo or just want to talk to some people from the project, this is a good chance to do so!

Visualizations for Models (16 Feb 2012)
As of now, almost all of our C extensions and DSLs are (semi-)textual, because graphical notations will be supported by MPS only starting from 2013. However, for many abstractions, graphical representations are useful to gain an overview over their structure. Examples include module dependencies, the relationships between components and interfaces as well as among components, or state machines with their transitions and guard conditions.
We have been generating graphviz files for a long time. Users had to open an external viewer to look at the pictures. More recently, however, we have directly integrated a viewer into MPS. It is based on ZGRViewer. Click on the screenshot to see it in full size.
The viewer has three interesting features beyond the fact that it renders graphviz images. The first one is that the diagrams support zoom and pan, thanks to ZGRViewer. The second one is that a click on a node or an edge selects the underlying element in the MPS editor. And third, the tree view at the top of the viewer shows all graphviz files in a solution, so users can quickly find the relevant graphs.

Hello C++ (07 Feb 2012)
We have started working on C++. As you can see in the screenshot, we can do the basic OO stuff, as one would expect (click on the picture to be able to read the code).
C++ is a really complicated language, and we haven't decided yet on how much of it we're actually going to implement. Especially the type system for the template stuff is really advanced. It would help us if you could let us know how much of C++ is typically used in embedded systems? Also keep in mind that many of the things that today are done with template meta programming can simply be implemented as a language extension with MPS!

Towards a Realistic Example (05 Jan 2012)
We have started building a comprehensive example using mbeddr C. We have selected Lego Mindstorms together with the nxtOSEK operating system. OSEK is a real-world embedded operating system, so our example does have some real-world relevance.
The main two reasons for builing the thing is that we need a showcase for our talk and booth at Embedded World 2012 and that we want to eat our own dogfood. The latter has already proven a good idea, we're finding bugs, problems and places for improvements left and right (and we're addressing them of course).
As of now, we have the motors, the gun and the compass at work (the compass is the thing on the big pole --- we try to avoid interferences). Next will be the bumpers, the light sensor and the sonar. A lot of fun :-)

Tesing Components with Stubs and Mocks (02 Jan 2012)
As mentioned before, we consider components as one of the most important extensions provided by mbeddr C. A big advantage of the component-based approach is that the specification of behavior is separated from the implementation. This way, the same interface can be implemented by different components. A particular interesting use case for this feature is the implementation of interfaces specifically for testing purposes as stubs and mocks.
A stub component is a component that implements "dummy" behavior to be used in a test case. Essentially, a stub is just a normal implementation, but it provides counters regarding how often an operation (or port, or the instance in total) has been called. The figure below shows an example. The built-in expression opCallCount is used, together with the in operator, that checks a value for membership in a range.
Mocks are more interesting. They are used to verify that another component behaves as expected. To this end, a mock specifies the expected behavior it wants to see on a provided port. The example below shows a mock component that provides a port the implements PersistenceProvider, which provide the isReady, store and flush operations. The mock specifies that, in a given test case for which the mock is defined, it expects 4 operation calls in total. It specifies a sequence of calls; the first one expects isReady, and returns false. The second expected call is again isReady, but this time we return true. We then expect store to be called, and we check that the data argument is not null. Finally, we expect flush to be called.
A mock component can be instantiated and wired up like any other component. Since a mock is expected to be used in a test case, there is a special new statement that verifies whether the actual behaviour conformed to the expected behaviour. The figure below shows an example. It fails the test case if the mock does not validate.
The mock specification language is a nice example of a DSL that makes sense to be integrated with C. We also reuse C's expressions in mock expectations. Stubs and mocks also illustrate nicely why a separation between interfaces and the implementation is a useful software engineering paradigm.



From Interfaces to Contracts (01 Jan 2012)
In a previous post we have talked about components and interfaces. We believe that components are an essential and widely applicable extension to C is the basis for meaningful reuse and variability management. In our approach, the same interface can be provided (implemented) by several different components, in different ways. Of course, the semantics implied by the interface should be realized consistently by all these components. To enforce this, an interface must specify more than just the signature of the operations.
We have implemented two additional facilities: pre- and post conditions as well as protocol state machines.
Preconditions express constraints over the arguments of operations when they are called. The figure below shows an example. In the add operation, two preconditions are used to make sure the arguments are greater than zero. Postconditions ensure that the result is positive and the result is the sum of the two arguments. The Computer component below, which implements the interface, will verify the correctness of these constraints when operations are called. If they are violated, the message associated with the pre or postcondition is reported. Note that the pre and postconditions are expressed over the interface, and all components that provide the interface automatically get the verification code.
Sometimes postconditions have to be expressed over the state of an object. Since interfaces cannot define state, we have to use query operations to access the state. A query operation is an idempotent operation, that can be called at any time to return a value. In the example below, the value operation is marked as a query and hence can be used in pre and postconditions. Note also how the old keyword can be used to access the result of the value operation before the operation is executed.
The other ingredient to contractual interfaces are protocol state machines. These can be used to enforce the sequencing of calls on an interface. Take a look at the code below. It defines a protocol for each operation. The openForWrite operation requires the protocol state machine to be in the init state, and when called, transitions to the writing state. Once in writing, you can call write any number of times and then call close to go back to the init state. Reading works similarly. Essentially, the protocol state machine in the example enforces that the file system can be used for writing only or for reading only. Close resets it. The init state is the default state available in any protocol state machine. The * state is a shorthand for any state. Using the new keyword, new states can be introduced, and those can be referenced from other protocols. An operation can have several protocols, they are or'ed together.
Pre and Postconditions and protocols can be mixed. This way, a relatively complete specification of an interface's semantics can be provided. The constraints are automatically checked on every implementing component, enforcing the contract.



Why mbeddr uses MPS (20 Dec 2011)
At JetBrains TV we have recently contributed a little video that explains why we use MPS. The video is also a nice demo of some of the features we have in mbeddr :-)
Extension Guide is now online (12 Dec 2011)
On the download page we have now published some material on extending the mbeddr C language. This includes the mbeddr Extension Guide and a couple of links to general MPS documentation.
First Code Available as Early Access Preview (10 Dec 2011)
We have reached a significant milestone today: we have released a first snapshot of the mbeddr core code including a user guide and an example project. Take a look at the Get it! page to find out more. We hope you enjoy our little christmas present :-) We're looking forward to receiving feedback about what you think.
mbeddr in the cloud: our new integration server (09 Dec 2011)
We now have a continuous integration server for the mbeddr project. JetBrains is giving away Teamcity licenses for open source projects, and we've gotten one (a very nice tool, by the way. Thanks guys :-)). We've set up a server "in the cloud" so the whole team, and in the future, users, are able to access it. We now have continuous build, test and creation of distro ZIP files.
This is also important from another perspective: future users will want to be able to build and test their mbeddr C programs automatically on a build server. We now do that with all our test cases. So we've solved that problem :-)
On the road to Open Source (01 Dec 2011)
We are currently working on fixing the last (known) bugs and writing a user's guide (currently 30 pages). When we open source the core C language, we want to make sure users have a good shot at understanding what we did and how to use it.
So: nothing concrete yet, but I thought I'd let you know we're not doing nothing :-)
Model Checking: A First Cut at Tool Integration (17 Nov 2011)
A major advantage of DSLs is that it is easier to apply formal verification techniques on their programs. As example, state machines can be formally analyzed in order to detect typical bugs such as: dead states, dead transitions, or non-determinism (when from a state, under certain circumstances, several transitions can be fired simultaneously). Additionally the users can define different custom checks by using an intuitive DSL. For performing analyses we use in the background the NuSMV model checker (a concise and readable introduction to model checking can be found in this book).
Our aim is to empower developers without any knowledge on mathematical logics to use formal analyses techniques. The workflow is simple and transparent to the user: once a state machine is marked as verifiable, the MPS checks wether it is written in a language subset that we can analyze. If yes, then the context menu then contains an action to run the model checker. The results of the model checker run are displayed nicely in a table:
For each of the predefined (or custom-defined) checks, the table states whether it succeeded or failed. If it failed, the table contains an example that shows how the check is violated. The table shows the example state sequence and the values of all variables. A user can click on the respective state to get it selected in the source.
The goal of integrating model checkers in mbeddr is to make model checking (almost) as easy as writing test cases. This way, we aim to convince more users of the idea that model checking (and formal verification in general) can be used in the daily work of embedded development.

A Week of Coding (17 Nov 2011)
This week we had a team meeting at itemis in Stuttgart. We discussed how we'd proceed with implementing C extensions for Lear and Sick. We also cleaned up our code base, fixed bugs, tested, and started setting up a build server. We are well on our way for a mid-december release of an EAP version of the C base language for MPS. Stay tuned :-)
Tutorial updated for MPS 2.0 (09 Nov 2011)
Just a quick update: we migrated our MPS tutorial for MPS 2.0. If you want to get started with MPS, please have a look at the LWC11 example with MPS At the same time we updated to a real VCS aka. git :-) Have fun projecting. :-)
Support for Requirements Traceability (04 Nov 2011)
We have a first cut at supporting traceability into requirements. This consists of two parts.
Part one is a DSL for specifying requirements. A requirement has an ID, a summary, a prose text and any number of child requirements. A requirement also has a kind (e.g. functional or operational). The kind determines which additional specifications have to be provided. Any DSL can be "plugged into" the requirements framework to provide formally specified data to requirements. Requirements can also have constraints among each other. And of course, the requirements themselves, the kinds and the constraints can be extended by users of the system.
The second part of the system is traceability. A requirements trace annotation can be added to any other program element, expressed in any language. A trace points to one or more requirements and includes a trace kind (such as implements or tests).
Using this approach (and an importer from other requirements management tools we'll build in the future), flexible and extensible requirements traceability is supported for the mbeddr project.

A custom Outline View (20 Oct 2011)
Just like Eclipse, MPS supports views (they are called Tools in MPS). As an example of how to implement editor-synchronized additional tools, we have implemented an outline view. It shows the structure below the currently edited root up to a given level. This level, and the kinds of elements that are shown in this view, is determined by attaching annotations to the language concepts. If a concept has the show in outline annotation, will be shown in the view.
It is really nice to be able to attach any additional data to language definitions using concepts. Instead of coming up with an additional viewpoint model, this often small additional data can just be specified inline as part of the language concept definition itself.
Make is now integrated into MPS Build (20 Oct 2011)
We have integrated the make tool into the MPS build process. As part of the low-level code generation, a Makefile is generated. Now this Makefile is executed directly from within MPS during the build process MBEDDR C programs. This is useful in its own right, and it also taught us how to integrate additional steps in the build process in general. So if other target platforms have additional build steps, we now know how to integrate those as well.
Error Reporting (15 Oct 2011)
Reporting errors is surprisingly non-trivial in embedded systems. You can't simply printf stuff. There may be no stdlib, and there may be no console :-) In many embedded systems there is no way of error logging, everything must be tested thoroughly, so there are no errors left. Alternatively, there is usually some kind of memory area, where log messages and error statuses are collected ("Fehlerspeicher"). So we came up with a first cut at a simple error reporting approach. Here is some code:
We first define messages. These have IDs, an error test, a classification (ERROR, WARN, INFO) and, later, a numerical code and additional log data. Reporting an error happens via the code shown in the function: a message is references and reported, possibly only if a certain condition is met. Messages can be disabled, in which case the report statements that report those disabled messages are not generated into the code --- no reporting, no cost.
Depending on the target platform, the report statements are either transformed simply to a printf, or to writing into some kind of error memory. Platform-dependent language concept translation is an important ingredient to our approach, and illustrated, albeit with a simple example, by the error reporting feature.

Refactoring Support (02 Oct 2011)
A good IDE provides useful refactoring support. Since we're planning to build a really good IDE for C, we have started adding a couple of them. Here is the list that is currently supported:
- Extract Into new Module: one or more module contents (functions, variables, statemachines, etc) can be selected and moved into a new module. The system prompts for the new module's name, creates it, moves the contents there and then adds an import of the new module to the original module. The contents in the new module are set to be exported if they are referenced from the original one.
- Move to Imported Module: similar to the previous one, but this one does not create a new module. Instead it moves the selected contents into one of the modules that are already imported.
- Introduce Variable: an expression, maybe a sub-expression of another one, is selected. The refactoring then prompts for a name, and proceeds to create a local variable with that name. The type of the variable is the type of the selected expression and the init value is the expression itself. The occurrence of the expression is replaced by a reference to the new variable.
This is obviously a small list, but it was only three hours work. MPS provides a DSL/API for expressing refactorings, and it is relatively straight forward to implement those. MPS also provides support for data flow analysis. That's a topic we'll have to investigate soon, so we can build more sophisticated refactorings.
Decision Tables (26 Sep 2011)
One thing that is nice about the projectional editor in MPS is that you cannot just use textual notations, but also, for example, tables. We've built a little decision table. It uses a two-dimensional tabular projection to render the two dimensions that are and'ed together. Below is an example and a test case.
We've also added a gswitch expression, it's a generified switch that can be used in expression context. It can use any boolean expression in the cases and is translated to a bunch of if/else statements wrapped in an inline function to put it into expression context. The decision tables are translated to nested gswitch expressions.

A first cut at statemachines (23 Sep 2011)
We have got a fist cut of a state machine language. Our languages supports the declaration of in- and out events, entry and exit actions for states, transitions between states with guard conditions and transition actions. In-events are transmitted from the environment into the state machine while with out-events the machine can notify its environment. Both event types have optional parameters. In addition, a state machine can define local variables. Similar to components, state machines can be instantiated multiple times.
State machines are logically independent entities which can be embedded in different contexts. We have already built an integration with ordinary modules as well as components, so state machines can be embedded into modules and components. Dependent on their environment, they can bind their out events to either a regular C function call, a call to an operation provided by a client-server interface or a message which is sent through a message interface of a required port.
We also started with building an integration with the NuSMV model checker which supports static verification of the correctness of a state machine. One very important feature here is that a state machine can be verified independently from where it's embedded. This is possible because a state machine's internal behavior only depends on the events and not on their bindings.
A quick heads-up (21 Sep 2011)
So we are making progress :-) By the beginning of next week we should be "operator complete". The remaining primitive types should by in by end of September. We have prototyped a first integration with a model checker and implemented a first cut of a statemachine language. As it seems now, we will publish a first Open Source version of the core C language during November 2011.
FAQ added (01 Sep 2011)
So, people really do ask the same set of questions over and over again :-) So we've collected those questions, and brief answers, on the new FAQ page.
First Cut at Components (16 Aug 2011)
We have started implementing interfaces, components, ports, instances and connectors. At this point we can work with connected atomic components (no composite components yet). Here is some example code:
Turns out, that in order to implement component instances which can each be connected to different other components, we have to introduce a struct with functions pointers that keeps track of the wirings on a per-instance bases. The function references we implemented recently did a marvelous job here :-)
Next up is the support for composite components.

Now with Closures :-) (10 Aug 2011)
Once we had function references and higher order functions, of course we thought about implementing closures. The following screenshot shows the syntax we have chosen:
From the closures, we generate a function whose pointer we then pass to the higher order function. So we map the closure mechanism to the function pointer stuff we did before. Also, we don't support references to local variables from within closures. "Transporting" their values along with the closures would certainly be possible, but would lead to quite some overhead. Since we're targetting embedded systems, we decided that that's not a good idea.
Notice also that the parameters don't require the specification of a type. We use type inference to automatically calculate the type from the context.
You know what's the coolest thing about the closures? It took just three hours to implement them. Syntax, generator, type inference and all. MPS really is neat :-)

Function References and Higher Order Functions (4 Aug 2011)
C has always had support for higher-order functions using function pointers. Today we have added this feature to our MPS-C implementation. We have cleaned the syntax up a bit (C's syntax is awful here!) to resemble Scala's. Here is some example code:
Here is the cool thing: we spent just three hours to add this feature to C. This includes syntax, type systems, quick fixes and the (relatively trivial) generator to C text. This clearly speaks to the power of MPS!
This week we also added enums to C, created a state machine language prototype, as well as a prototype for configurable counters. This is a lot of fun :-)

Differences to regular C (30 Jul 2011)
Here is a list of differences to regular C.
- We don't support the preprocessor. Instead we will provide first class concepts for all the various use cases of the C preprocessor. This avoids some of the chaos that can be created with the C preprocessor.
- While we generate header files, we don't expose them to the programmer in MPS. Instead, we have defined modules as the top-level concept. Modules also acts as a kind of namespace. Module contents can be exported, in which case, if that module is imported by another module, the exported contents can be used by the importing module.
- We have introduced a specific Boolean datatype. Integers cannot be used as Boolean. in all of to call legacy functions, the wrapper construct will be provided.
- In the switch statement, we don't use the annoying fall through semantics. Only one case within the switch will ever be executed, since we automatically generate a break statement into the generated C code.
- The language has direct support for test cases (as module contents)
- Array brackets must show up atter the type, not after the variable name
- The * for pointer types must show up after the type, not before the identifier (i.e. int x vs. int x)
- At this point a local variable declaration can only declare one variable
There are various reasons for these differences. For some of them, we feel we are compensating weaknesses of C (int vs boolean). For others, we exploit the capabilities of MPS and the generative approach (modules). Yet others just make our lives as implementers more pleasant (arrays and pointers after type instead of variable name).
Pointers, Arrays, Globals (30 Jul 2011)
We now have arrays, pointers and globals working. This pointer stuff is quite non-trivial in C, especially regarding type checks. But all our tests work :-). We're making good progress.
Talk about the Project in Stuttgart on Sept. 20 (24 Jul 2011)
On Sept. 20 there will be a chance to learn about the project in some detail, during a talk Markus Voelter will give in Stuttgart as part of the itemis talks series. Find details in this PDF. It would be cool if a couple of you guys would show up :-)
Working with MPS and Git (24 Jul 2011)
Some people are still skeptical regarding how to work with existing version control systems in the face of MPS' XML storage. Do diffuse that skepticism, here is a little video of how we use git and MPS together. The essential take-away is that MPS' projectional editor is used for doing diff and merge in case of conflicts.
Simple Build tools and Unit Tests working (24 Jul 2011)
We are making progress with our C implementation. We have implemented a make language so we can create makefiles for GCC. On top of that, we have implemented a build configuration language where we simply reference the modules that should go into an executable, and the corresponding makefile is generated.
We have a simple logging language which, because of the fact that we generate the code from the logging statements, can be turned off without overhead and automatically inserts into the code the location of the log statement, making it easy to understand the context of the log message.
We have also made progress with the unit testing support. We can now declare test cases with assert statements and run them from within make. We can also build the programs and run the tests completely from the command line. Here is a sample test case:
Finally, we have also implemented expression blocks, which allow you to use a block of statements where C expects an expression. The generator reduces this to an additional function and a function call to that function in place of the block expression. This is extremely useful for building generators. For example, the facility used to call test cases is based on this mechanism.
So this was a very productive weekend :-)


First C Code working (17 Jul 2011)
As you may know, our project relies on the idea of extending the C programming language with domain specific extensions. For that to work, we first have to make C available in MPS. While we had done this to some extent in our proof of concept, we are now implementing C much more thoroughly. As you can see in the screenshot below, some essential things are already working.
We have functions, local variables, basic expressions, a for statement, and other doing blocks. All of this works with a text generator and a type system. We are doing this breadth first and not depth first, which means that we're trying to try touch every aspect of C instead of implementing all available operators for example. Once the basic structure is there, we can then fill in the holes.
One of the next steps will be support for unit testing, so we can directly start testing our type system and code generators.
By the way: the core C language will be open sourced as soon as we have a reasonably complete implementation.

Kickoff Meeting (14 Jul 2011)
Today we had our kickoff meeting at Fortiss in Munich. Almost all of the people who will participate in the project were there. We discussed organizational things, but also concrete next steps. These next steps will include the collection of the requirements from our validation partners, as well as concrete plans to start the implementation of a more or less complete C in MPS. We also decided that the C implementation will be completely open source, so you will be able to use it for your own purposes. We also discussed a little bit how formal methods and model checking will play into the project, and I am very much looking forward to seeing how this will turn out. It was a great meeting, and I am very much looking forward to this project. I'm sure it's going to be a lot of fun. /Markus
MPS Screencasts added (11 Jul 2011)
At the bottom of the MPS page I have added a set of 8 screencasts, 90 minutes in total, about language modularization and composition with MPS.
Good News Confirmed (19 Jun 2011)
We now have the official word that our research project has been accepted. The kickoff will be on July 14. We now have 10 person years in total to work on DSLs for embedded development, integration with formal methods, and MPS. We will attempt to make this a very focused and open project, with possibilities for collaboration for third parties. Stay tuned!
Good News (06 Jun 2011)
Rumors are, our research project has been accpeted. This means we will expand the team and put much much more work into the project. Stay tuned :-)
Code available for Download (23 Jan 2011)
The MEL code is now available for download, as opposed to checking it out from the SVN. Note that in order to run it you need the latest MPS (1.5.1).
MEL/C Hello World Tutorial (23 Jan 2011)
A new Hello World Tutorial is available for the modulare embedded DSL. It takes you through writing your own little MEL program including functions, state machines and tasks.
mbeddr.com website created (09 Jun 2010)
This is the first post on the mbeddr.com website. The purpose of the site is track and document the embeddded software development tools we are currently building based on MPS.